CS & Support: how a snapshot of both helps your team. Metrics
What does your company see when it takes a joint snapshot of CS and Support?
Hint: many times it’s the image that confirms a design failure, not a people problem.
I’ll say it plainly: keeping CS and Support measuring different worlds creates wrong decisions. And wrong decisions translate into lost money, churn and more unproductive meetings.
Approach
Support measures tickets. CS measures customer health.
But if each one lives from its own dashboard, the result is predictable: Support optimizes resolution and CS optimizes retention.
Neither fixes the root cause.
Neither forces Product or Sales to change.
Tension / twist
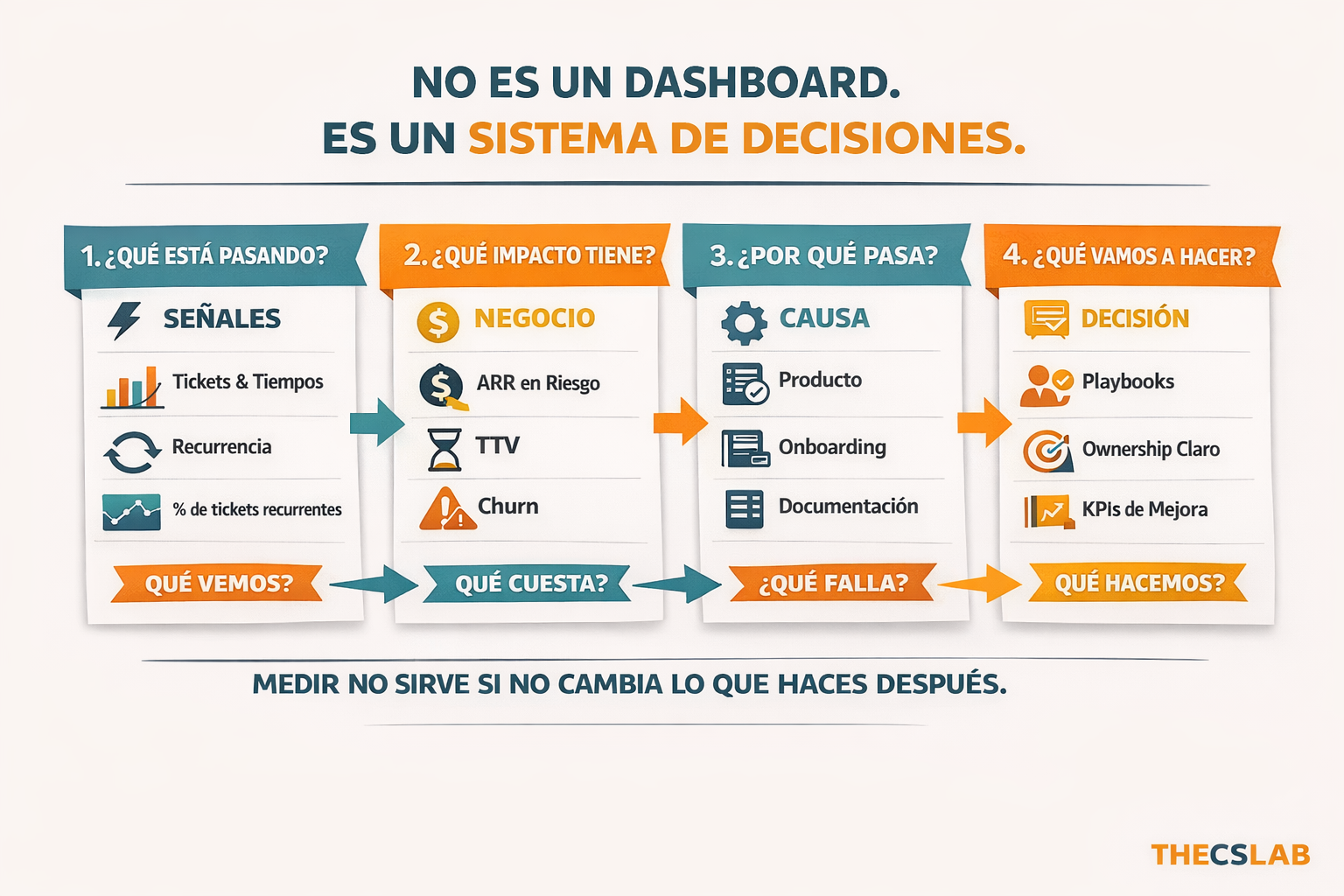
The snapshot I propose is not aesthetically pleasing, but operationally useful, as it combines signals (tickets, response time) with impact (ARR at risk, TTV) and causes (why the ticket repeats). If you don’t bring those layers together, your team keeps putting out fires.
Framework: “Single Snapshot CS+Support” (4 layers)
- Signals (capture)
- Ticket volume by product/module
- Average time to first response and to resolution - percentage of recurrent tickets
Why it matters: reveals operational friction and usage spikes.
2. Impact (economic weight)- ARR exposed by customers with >X tickets/month
- Average TTV by cohort (how long it takes a customer to achieve the key value)
- Churn for customers with a support history in the last 90 days
Why it matters: translates noise into real risk for the account and for the company.
3. Cause (diagnosis)- Root categories: product, onboarding, documentation, sales expectation
- % of tickets that result in escalation to Product
- Average time to resolve the root cause
Why it matters: without this you keep treating symptoms.
4. Decision (action)- Playbooks triggered: mitigation, roadmap input, change in onboarding
- Ownership: who closes the root cause (Product, CS Ops, Support)
- Follow-up KPIs: reduction of recurrent tickets and improvement in TTV
Why it matters: the snapshot only matters if it generates a clear decision each time it is updated.
Metrics to stop prioritizing
Below are outdated metrics that will give you more noise than focus.
- Number of calls or emails as an end in themselves. Don’t reward activity; reward impact.
- Isolated CSAT without correlation to recurrent tickets or ARR at risk.
Governance and rhythm
If we only do a one-shot, the effort will have been for nothing. Therefore, to manage and design the cadence and responsibilities so this becomes a habit and you can reap all the benefits, I propose:
- Cadence: a weekly “snapshot” for operations, and a monthly strategic review with Product and Sales.
- Owner of the snapshot: CS Ops (responsible for integrating it) + Support representative + Product Manager.
- Automatic triggers: if exposed ARR > 3% in a week, a mitigation play is called.
Expected outcome (if you do it well)
With this framework that I have tested, the result I have obtained is the reduction of those temporary patches that, if you stop and ask yourself how many you have, are surely more than you’d like, more than you’d want.
Therefore, if you follow it, your decisions will be more proactive, and churn will have fewer “inevitable” causes. And yes, this is not an isolated technical recipe; it demands a change of philosophy, of architecture, and it requires real changes on the board involving product, onboarding and sales.
And you, do you measure to decide, or do you measure to justify work?
Because if your weekly snapshot does not generate at least one operational decision, then it’s not a snapshot: it’s a pretty file. What decision would your last CS and Support snapshot generate?
Artículos relacionados